很多司法系统都奉行“无罪推定”原则,指一个人在法院上应该先被假定为无罪,除非被证实及判决有罪。也就是说,要驳回原假设(reject H0,the suspect is not guilty*)需要举证的证据比较严格。在这里第一型及第二型错误(Type I & Type II error)分别是:
- Type I Error: False Positive, reject H0 when it is actually true.(“冤案”:相当于嫌疑人其实无辜,但却判了他有罪。相对于Type 2 error可能性比较小。)
- Type II Error: False Negative, not reject H0 although H1 is actually true. (”错案”:相当于嫌疑人其实有罪,但是却被无罪释放了。相对于Type 1 error可能性较大。)
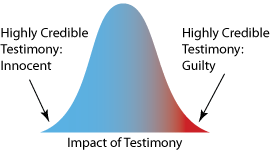
假设有个嫌疑人是无辜的。上图所示的正态分布表示对无辜嫌疑人进行审判时,所有证人可能的证词的分布。
- 分布左尾代表的是确信嫌疑人是无辜的、高度可信的证人。
- 右尾代表的是错误地认为嫌疑人有罪的、高度可信的证人。
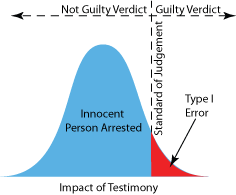
如果评估证词的判决标准定位如上图所示,并且只有一名证人作证,如果证人的证词在红色区域,无辜的嫌疑人将被判有罪(Type I error)。由于正态分布扩展到无穷大,即使判断标准移到最右边,Type I error也永远不会为零。防止所有Type I error的唯一方法是不要逮捕任何人(“无为”)。不幸的是,这将使逍遥法外的罪犯或Type II error的数量增加。
没有证据驳回原假设,并不代表原假设就是正确的,只是暂时缺少驳回原假设的信息(Not guilty != innocent)。如果用动态的观点来看待这个过程,那么所谓“现状”就是我们需要去驳回的原假设。如果我们思想越保守(Signficance level, alpha, is small),那么驳回已经形成的价值观所需要的证据也就越多。这种“保守”是基于对“人权”的尊重,也是具有统计意义的。“无罪推定”原则里的司法系统认为,“冤案”比“错案”更可恶。因为“冤案”不但让本应有罪的人逍遥法外,还让本来无辜的人铛锒入狱。
如果说人在做决策时,优化目标函数中包含主观情感因素的话,那么主观的部分也就因人而异。客观因素诸如金钱地位等等都可以有效量化,然而主观部分又该如何衡量呢?现有的普世价值观是基于大众的决策目标函数的,而相互独立的个体的主观部分服从某种分布。那么运用中心极限定理,那么优化函数中主观情感因素的参数便是可测的。但是这需要很多前提:样本量足够大(陪审团还是全民公投?),独立个体主观部分分布已知…
可见,想要制定一个合理的司法系统并没有那么简单。
