Preface
Today we are going to read an interesting paper on JMIS 2016 - Targeted Twitter Sentiment Analysis for Brands Using Supervised Feature Engineering and the Dynamic Architecture for Artificial Neural Networks, which take use of some machine learning techniques to investigate brand marketing on social media.
Targeted Twitter Sentiment Analysis for Brands
Basic information
Ghiassi et al, 20161 present a targeted approach to Twitter sentiment analysis for brands using supervised feature engineering and the dynamic architecture for artificial neural networks.
Methodologies
- Design Science
Based on Ghiassi et al, 20132:
Supervised feature engineering: The goal in supervised feature engineering is to select a set of features representing the tweet’s content and the sentiment expressed. which consists of five stages:
- Frequency analysis
- Affinity analysis
- Negation and valence shifter analysis
- Feature sentiment scoring
- Aspect categorization.
Dynamic architecture for artificial neural networks (DAN2)
Following supervised feature engineering, the tweet feature representation values are provided as input to the DAN2 3 for sentiment analysis and classification.
The DAN2 architecture is composed of an input layer, hidden layers, and an output layer. In DAN2, unlike classical neural nets, the number of hidden layers (However, a fixed number of hidden nodes (four) is used in each hidden layer) is not fixed a priori. They are sequentially and dynamically generated until a level of performance accuracy is reached.
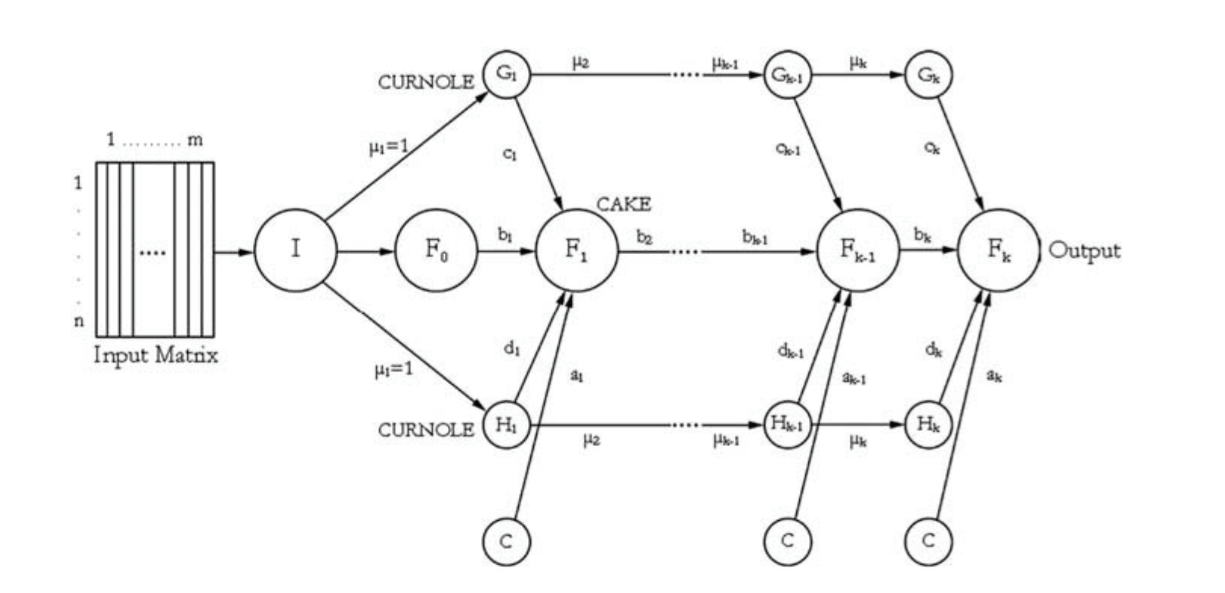
- We also develop comparable SVM models that are provided the very same features and instances as input.
Data
We collected tweets containing the @Starbucks or @GovChristie handles from the Twitter API to develop each brand-related tweet data set. During three months from August 18, 2013, to November 6, 2013, 442,443 tweets @Starbucks and 201,821 tweets @GovChristie were collected.
Variables
We ranked the sentiment scores output by the Repustate system, and identified the thresholds in score that would maintain the sentiment class distribution observed in the training data set.
Tweet Sentiment Classes:
- Strongly positive
- Mildly positive
- Neutral
- Mildly negative
- Strongly negative
Conclusions
- The results indicated the DAN2 and SVM machine-learning models that used the tweet feature representations derived through the proposed supervised feature engineering approach for brands outperformed the state-of-the-art Sentiment140 and Repustate TSA systems by wide margins, with classification precisions and recalls often above 80 percent.
- The DAN2 machine-learning model outperformed SVM in nearly every brand case and sentiment class, demonstrating particularly excellent recall of tweets expressing mild sentiments
Contributions
- We developed a reduced feature representation specific to TSA. Reducing the dimensionality of the tweet feature representation also reduced problem complexity, increased the density of the feature matrix, and mitigated the classical feature sparsity problem.
- We expanded the number of sentiment classes from three to five, included mildly positive and mildly negative classes, to target the mild sentiment expressions of particular interest to firms and brand management practitioners.
- We also further evaluated DAN2 as a machine-learning model for tweet sentiment classification.
- We evaluated the proposed approach on two brand-related cases in this study, and with the brand- related case examined in prior research 2, continued to develop a general and reusable feature set for TSA that can be applied across domains.
Limitations
Twitter data sets are limited in size: Manual annotation of tweets to create gold- standard sentiment class labels for classifier training and evaluation is a laborious and time-consuming task;
Summary
- There is lots of papers using sentiment analysis as an independent variable to study the financial market (Stock ect.) or E-Commerce (Amazon ect.). But most of them are using only 3 classes (Positive, neutral and negative) for the sentiment(see Literature Review on UGC/WOM). However, this paper represents that using feature engineering process and nueral network, we can generate multilevel sentiment for social media data set.
- Most of the papers investigating the impact of UGC (online news, such as Seeking Alpha, WSJ ect) on financial market are using simple regression (see Literature Review on Social Media in Financial Market). There is still limited research using machine learning method to investigate the impact of UGC on financial market.
1. Ghiassi, Manoochehr, Zimbra, David, Lee, Sean (2016). Targeted Twitter Sentiment Analysis for Brands Using Supervised Feature Engineering and the Dynamic Architecture for Artificial Neural Networks. Journal of Management Information Systems, 33(4), 1034—1058 ↩
2. Ghiassi, Manoochehr, Skinner, James, Zimbra, David (2013). Twitter brand sentiment analysis: A hybrid system using n-gram analysis and dynamic artificial neural network. Expert Systems with applications, 40(16), 6266—6282 ↩
3. Ghiassi, M, Saidane, H (2005). A dynamic architecture for artificial neural networks. Neurocomputing, 63(), 397—413 ↩
